Introduction¶
Divolte Collector is a solution for collecting clickstream data from website users and subsequently store that data into Hadoop as Avro files and push individual click events as messages onto a Kafka topic. This is useful in scenario’s where you need to perform off line and/or near real-time processing and analysis on user behavior in the form of click event data, such as when building recommender systems, personalization of websites or plain analytics on user behavior on a website.
Several solutions exist already to this problem (hosted solution like Google Analytics, Omniture, or open source systems such as Piwik). Here’s what makes Divolte Collector different:
- Built from the ground up for Hadoop and Kafka (Divolte Collector writes directly to HDFS and Kafka; no plugins or integrations).
- The collected data has a user defined schema, with domain specific fields in Apache Avro records; Divolte Collector allows for schema evolution as well.
- The above means that click event URLs are parsed and transformed on the fly; this is done based on rich configuration, so no custom coding required.
- Because Divolte Collector is built for Hadoop and Kafka, it comes with several working examples for using your data in Apache Spark, Apache Hive, iPython notebook with PySpark and using a Kafka Consumer. Because Avro records are used, these use cases are supported without requiring log file parsing or complex integration.
The remainder of this chapter introduces the concept of clickstream collection and the way Divolte Collector solves this problem. If you’d rather get hands-on immediately, why not jump to the Getting Started guide.
Capturing clickstream¶
Click events are the primary data source in web optimization solutions. These events are often captured through log (file) processing and pushed down to systems for both batch and near real-time processing. So, capturing the click event data from web visitors in order to analyze and act upon user behavior is not a new problem. Over time, it has been solved in different ways, all with their own advantages and drawbacks. First, let’s look at a typical architecture for building web optimization solutions:
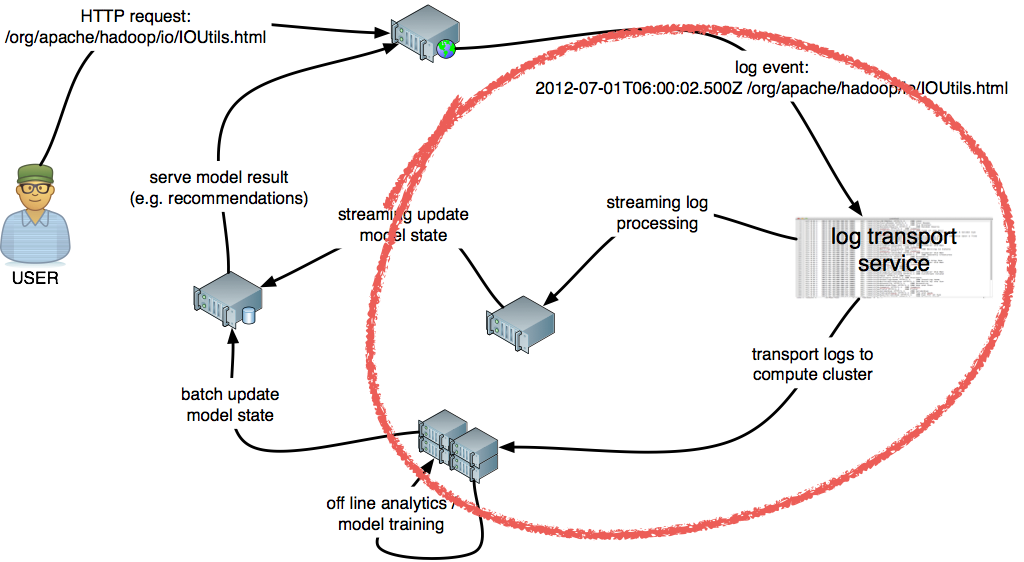
In the above diagram, the part marked in the red outline is the problem that Divolte Collector focusses on: the collection, parsing, storing and streaming of click events.
The simplest solution to this problem (and also the one that most of the early Hadoop use cases were based on), is to simply collect the web server log files and push them onto HDFS for further processing:
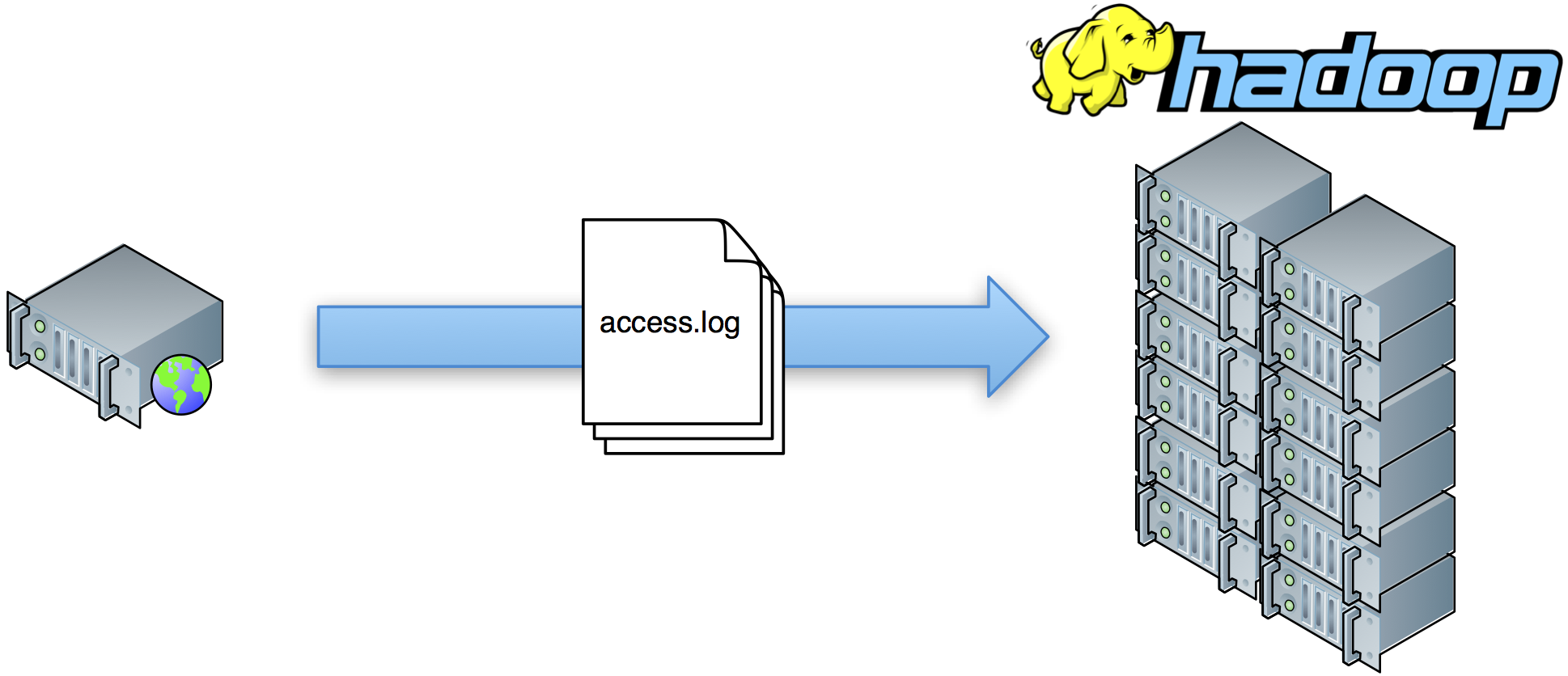
This method has some drawbacks, however:
- It is inherently batch oriented; no near real-time flow.
- No schema. Log events are just lines in the web servers log format.
- This requires an initial job to just parse out the relevant information.
- Usually multiple versions of this parser are needed.
- Requires sessionizing.
- Log contain a lot of non-user requests, such as bots, crawlers, health checks, etc.
In order to overcome some of these problems, the next generation of log event collection setups would stream individual log events instead of moving entire log files around. This can be solved using a combination of tools like syslog, syslog-ng and Apache Flume.
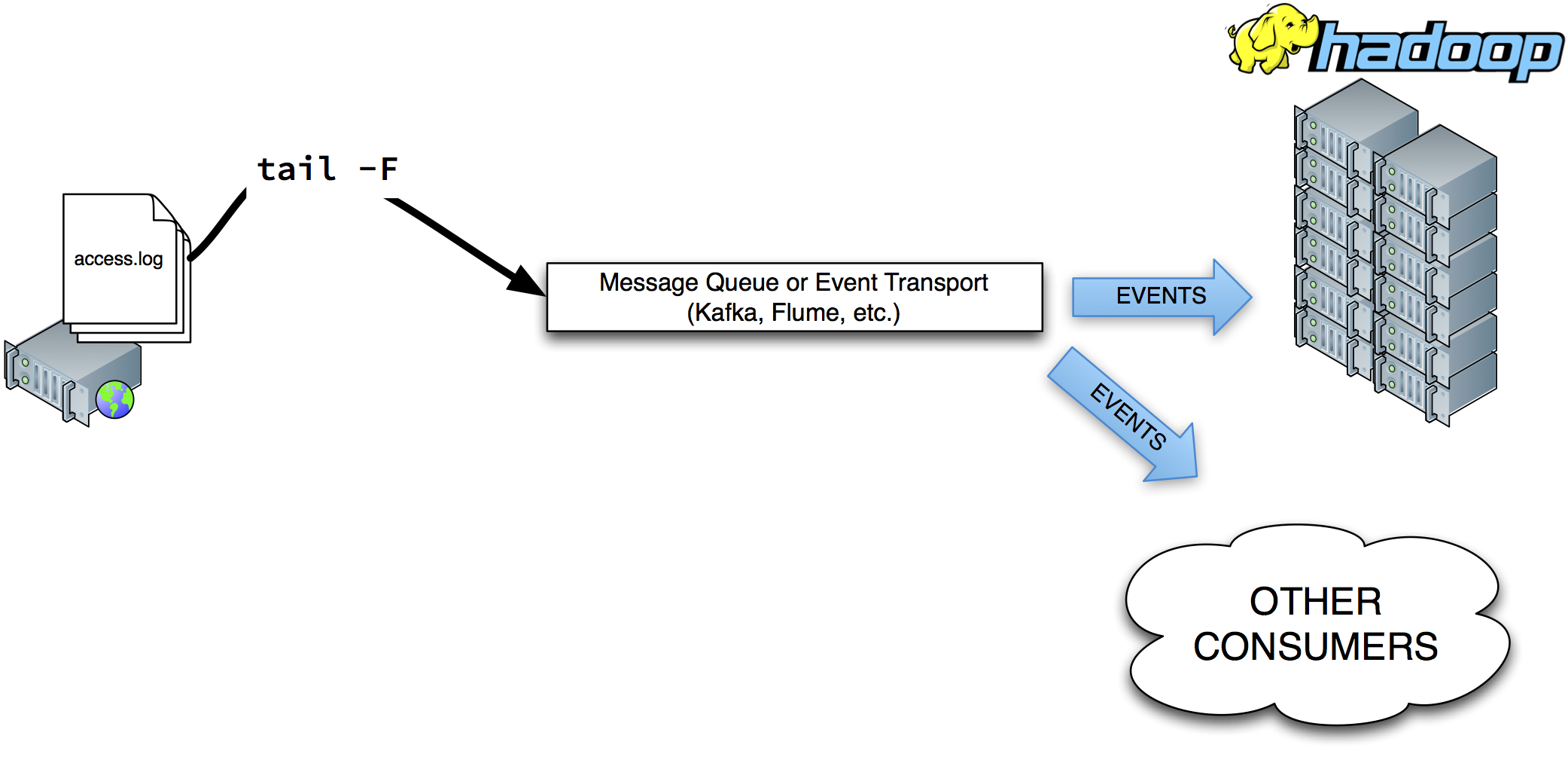
While this adds streaming processing to the mix, some drawbacks still exist: there is no schema, you still need a parser and it suffers from bots and crawlers alike. That’s why, many of the more modern solutions take a different approach. Instead of using the server side log event as the source of event data, a event is generated on the client side, which actively calls a separate back-end serivce to handle the event logging. This method is often called tagging (or Web Bug, if you’re Wikipedia). In this scenario, each web page contains a special piece of JavaScript code that calls a back-end service to generate the actual event:
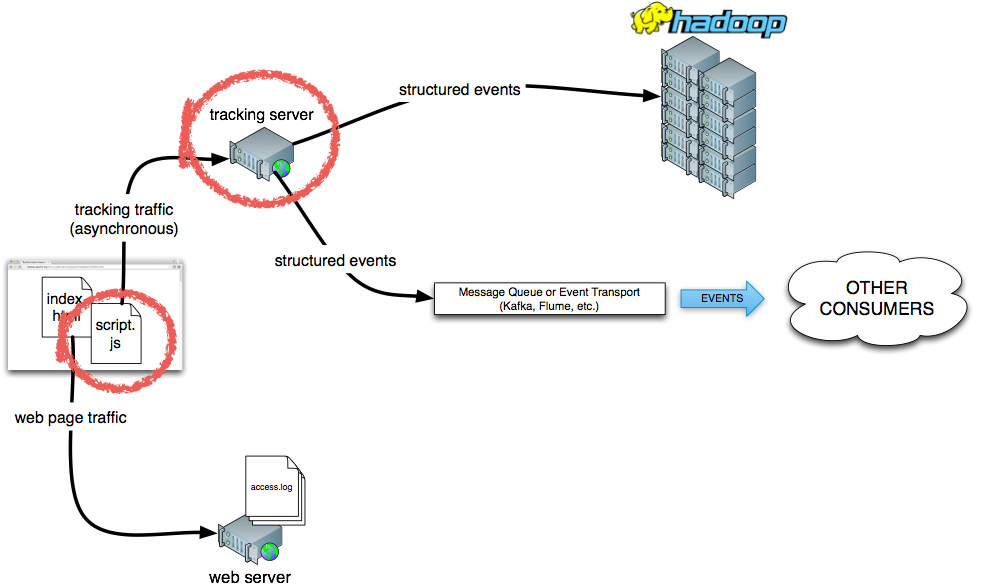
This approach has several benefits:
- Less traffic from bots and crawlers is seen in the event stream (most bots do not evaluate JavaScript).
- Event logging is asynchronous; it doesn’t compete with your web servers cycles or bandwidth.
- This makes it easier to do in-flight processing as it doesn’t influence the performance of the web page itself.
- It allows for custom events fired from JavaScript based on interactions that would otherwise not reach the server side.
- The JavaScript has access to some properties that the web server doesn’t see:
- Screen resolution of the client
- Viewport site
- Timezone
- The JavaScript can manage party en session identifiers on the client side
- This way the incoming data is already sessionized
This is the way Divolte Collector works. In the above diagram, the components in the red outlines are the core parts of Divolte Collector: a JavaScript tag that goes in each web page and a collection server that enriches events and writes them as Avro records to HDFS files and Kafka messages.
Features¶
In addition to collecting click events, Divolte Collector provides a number of welcome features:
- Single line JavaScript deployment: <script src=”//collect.example.com/divolte.js” defer async></script>
- Mapping click stream data onto a domain specific (Avro) schema; on the fly parsing
- Comes with a built in default schema and mapping for basic, zero-config deply
- Horizontally scalable behind a load balancer.
- Performs in stream de-duplication of events, in the case a broser fires the same event multiple times or other sources of duplicates exist
- This happens more often than you think on the internet.
- Corrupt request detection for similar issues as above.
- Generates unique identifiers:
- party ID: a long lived cookie that is set on the client
- session ID: a cookie that expires after 30 minutes of inactivity
- pageview ID: a unique identifier for each pageview and subsequent custom events fired from the same page
- event ID: a unique identifier for each event
- User agent parsing: the user agent string is parsed on the fly and the resulting fields (e.g. operating system, browser type, device type) can be mapped onto the schema.
- ip2geo lookup: on the fly geolocation lookup based on IP address can be done using the Maxmind databases.
- Defeat Google Chrome’s pre-rendering and many other browser quirks; this prevents phantom events where the user actually never saw the page.
- Fire custom events with custom parameters from JavaScript in your pages
- The custom event parameters can be mapped directly to your schema.
- It is possible to generate page view IDs on the server side when using dynamically generated pages.
- This allows to perform server side logging which can later be related to client side events.
- Divolte Collector comes with additional libraries to make it very easy to create custom Kafka consumers for near real-time processing and to work with your data in Apache Spark (Streaming).
- Built with performance in mind: in testing on commodity hardware, Divolte Collector should be network IO bound before anything else.
- In the default configuration, it handles about 12K-15K requests per request processing thread per second on a Linux VM running on a laptop.
Requirements¶
Divolte Collector is written in pure Java and runs on any OS that supports the latest JVM. For best result, we recommend running on Linux.
- JDK, version 8 or above (Oracle’s JDK is recommended)
- At least 1GB available RAM; depending on configuration
- Hadoop 2.0 or above (optional, see below)
- Tested to work against: CDH, HDP and MapR
- Apache Kafka 0.8 or above (optional, see below)
- Load balancer with SSL off loading to support HTTPS
Note: Divolte Collector can be configured to send data to either HDFS or Kafka or both. It’s not required to use both. When running locally for testing, it can also write to the local file system.