Mapping¶
Mapping in Divolte Collector is the definition that determines how incoming requests are translated into Avro records with a given schema. This definition is composed in a special, built in Groovy based DSL (domain specific language).
Why mapping?¶
Most clickstream data collection services or solutions use a canonical data model that is specific to click events and related properties. Things such as location, referer, remote IP address, path, etc. are all properties of a click event that come to mind. While Divolte Collector exposes all of these fields just as well, it is our vision that this is not enough to make it easy to build online and near real-time data driven products within specific domains and environments. For example, when working on a system for product recommendation, the notion of a URL or path for a specific page is completely in the wrong domain; what you would care about in this case is likely a product ID and probably a type of interaction (e.g. product page view, large product photo view, add to basket, etc.). It is usually possible to extract these pieces of information from the clickstream representation, which means custom parsers have to be created to parse this information out of URLs, custom events from JavaScript and other sources. This means that whenever you work with the clickstream data, you have to run these custom parsers initially in order to get meaninful, domain specific information from the data. When building real-time systems, it normally means that this parser has to run in multiple locations: as part of the off line processing jobs and as part of the real-time processing.
With Divolte Collector, instead of writing parsers and working with the raw clickstream event data in your processing, you define a mapping that allows Divolte Collector to do all the required parsing on the fly as events come in and subsequently produce structured records with a schema to use in further processing. This means that all data that comes in can already have the relevant domain specific fields populated. And whenever the need for a new extracted piece of information arises, you can update the mapping to include the new field in the newly produced data. The older data that lacks newly additional fields can co-exist with newer data that does have the additional fields through a process called schema evolution. This is supported by Avro’s ability to read data with a different schema from the one that the data was written with.
In essence, the goal of the mapping is to get rid of log file or URL parsing on collected data after it is published. The event stream from Divolte Collector should have all the domain specific fields to support you use cases directly.
Understanding the mapping process¶
Before you dive in to creating your own mappings, it is important to understand a little bit about how the mapping is actually performed. The most notable thing to keep in mind is that the mapping script that you provide, is not evaluated at request time for each request. Rather, it is evaluated only once on startup and the result of the script is used to perform the actual mapping. This means that your mapping script is evaluated only once during the run-time of the Divolte Collector server.
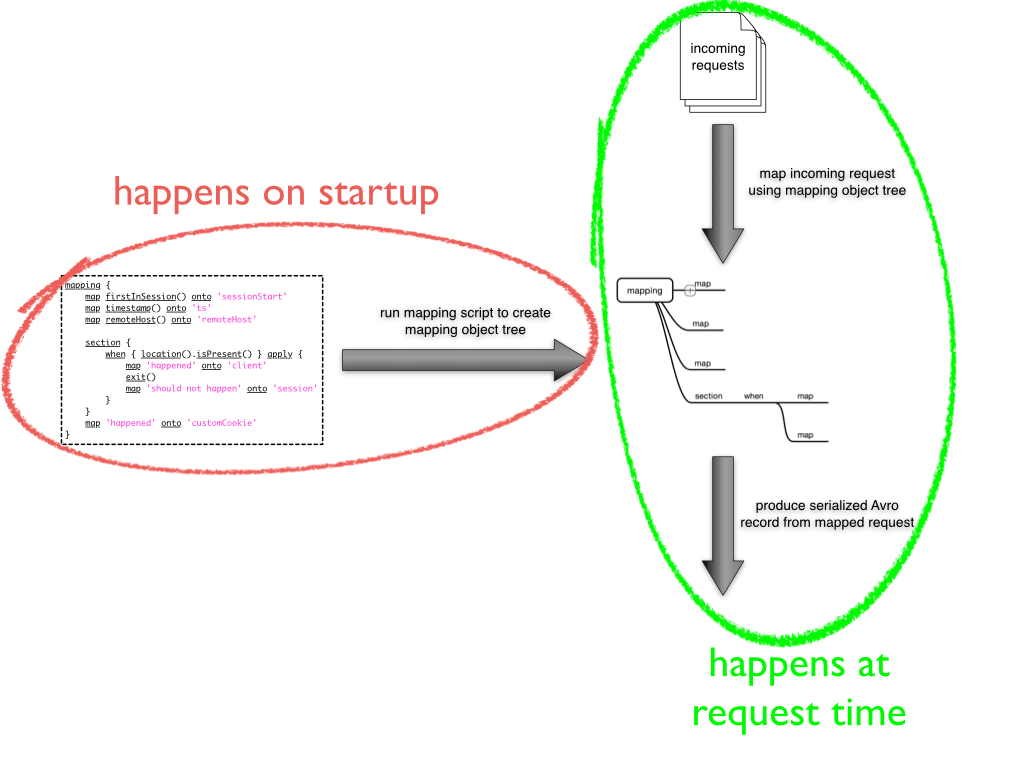
Built in default mapping¶
Divolte Collector comes with a built in default schema and mapping. This will map pretty much all of the basics that you would expect from a clickstream data collector. The Avro schema that is used can be found in the divolte-schema Github repository. The following mappings are present in the default mapping:
| Mapped value | Avro schema field |
|---|---|
| duplicate | detectedDuplicate |
| corrupt | detectedCorruption |
| firstInSession | firstInSession |
| timestamp | timestamp |
| clientTimestamp | clientTimestamp |
| remoteHost | remoteHost |
| referer | referer |
| location | location |
| viewportPixelWidth | viewportPixelWidth |
| viewportPixelHeight | viewportPixelHeight |
| screenPixelWidth | screenPixelWidth |
| screenPixelHeight | screenPixelHeight |
| partyId | partyId |
| sessionId | sessionId |
| pageViewId | pageViewId |
| eventType | eventType |
| userAgentString | userAgentString |
| User agent name | userAgentName |
| User agent family | userAgentFamily |
| User agent vendor | userAgentVendor |
| User agent type | userAgentType |
| User agent version | userAgentVersion |
| User agent device category | userAgentDeviceCategory |
| User agent OS family | userAgentOsFamily |
| User agent OS version | userAgentOsVersion |
| User agent OS vendor | userAgentOsVendor |
The default schema is not available as a mapping script. Instead, it is hard coded into Divolte Collector. This way, you can setup Divolte Collector to do something useful out-of-the-box without any complex configuration.
Schema evolution and default values¶
Schema evolution is the process of changing the schema over time as requirements change. For example when a new feature is added to your website, you add additional fields to the schema that contain specific information about user interactions with this new feature. In this scenario, you would update the schema to have these additional fields, update the mapping and then run Divolte Collector with the new schema and mapping. This means that there will be a difference between data that was written prior to the update and data that is written after the update. Also, it means that after the update, there can still be consumers of the data (from HDFS or Kafka) that still use the old schema. In order to make sure that this isn’t a problem, the readers with the old schema need to be able to read data written with the new schema and readers with the new schema should also still work on data written with the old schema.
Luckily, Avro supports both of these cases. When reading newer data with an older schema, the fields that are not present in the old schema are simply ignored by the reader. The other way araound is slightly trickier. When reading older data with a new schema, Avro will fill in the default values for fields that are present in the schema but not in the data. This is provided that there is a default value. Basically, this means that it is recommended to always provide a default value for all your fields in the schema. In case of nullable fields, the default value could just be null.
One other reason to always provide a default value is that Avro does not allow to create records with missing values if there are no default values. As a result of this, fields that have no default value always must be populated in the mapping, otherwise an error will occur. This is problematic if the mapping for some reason fails to set a field (e.g. because of a user typing in a non-conforming location in the browser).
Mapping DSL¶
The mapping is a Groovy script that is compiled and run by Divolte Collector on startup. This script is written in the mapping DSL. The result of this script is a mapping that Divolte Collector can use to map incoming requests onto a Avro schema.
Values, fields and mappings¶
The mapping involves three main concepts: values, fields and mappings.
A value is something that is extracted from the incoming request (e.g. the location or a HTTP header value) or is derived from another value (e.g. a query parameter from the location URI). Values in the mapping are produced using method calls to methods that are built into the mapping DSL. Below is the complete documentation for all values that can be produced. One example of such a method call would be calling location() for the location value or referer() for the referer value of the request.
A field is a field in the Avro record that will be produced as a result of the mapping process. The type of a field is defined by the Avro schema that is used. Mapping is the process of mapping values extracted from the request onto fields in the Avro record.
A mapping is the piece that tells Divolte Collector which values need to be mapped onto which fields. The mapping DSL has a built in construct for this, explained below.
Mapping values onto fields (map)¶
The simplest possible mapping is mapping a simple value onto a schema field. The syntax is as follows:
map location() onto 'locationField'
Alternatively, the map methods takes a closure as first argument, which can come in handy when the value is the result of several operations or a more complex construct, such as this example where we take a query parameter form the location and parse it to an int:
map {
def u = parse location() to uri // parse a URI out of the location
parse location().query().value('n') to int32 // Take the n query parameter and try to parse an int out of it
} onto 'intField'
In Groovy, the last statement in a closure becomes the return value for the closure. So in the closure above, the value returned by the parse call is the result of the entire closure. This is in turn mapped onto the ‘intField’ field of the Avro record.
Apart from mapping values onto fields, it is also possible to map a literal onto a field:
map 'string literal' onto 'stringField'
map true onto 'booleanField'
This is most often used in combination with Conditional mapping (when), like in this example:
when referer().isAbsent() apply { // Only apply this mapping when a referer is absent
map true onto 'directTraffic'
}
Value presence and nulls¶
Not all values are present in each request. For example when using a custom cookie value, there could be incoming requests where the cookie is not sent by the client. In this case, the cookie value is said to absent. Divolte Collector will never actively set a null value. Instead for absent values it does nothing at all; i.e. the mapped field is not set on the Avro record. When values that are absent are used in subsequent constructs, the resulting values will also be absent. In the following example, if the incoming request has no referer, the field ‘intField’ will never be set, but no error occurs:
def u = parse referer() to uri // parse a URI out of the referer
def q = u.query() // parse the query string of the URI
def i = parse q.value('foo') to int32 // parse a int out of the query parameter 'foo'
map i onto 'intField' // map it onto the field 'intField'
Because absent values result in fields not being set, your schema must have default values for all fields that are used for mappings where the value can be absent. In practice, it is recommended to always use default values for all fields in your schema.
Types¶
Values in the mapping are typed and the value type must match the type of the Avro field that they are mapped onto. Divolte Collector checks the type compatibility during startup and will report an error if there is a mismatch. The type for a value can be found in the documentation below.
Below is a table of all types that can be produced in a mapping and the corresponding Avro schema’s that match them:
| type | Avro type |
|---|---|
| string | { "name": "fieldName", "type": ["null","string"], default: null }
|
| boolean | { "name": "fieldName", "type": ["null","boolean"], default: null }
|
| int | { "name": "fieldName", "type": ["null","int"], default: null }
|
| long | { "name": "fieldName", "type": ["null","long"], default: null }
|
| float | { "name": "fieldName", "type": ["null","float"], default: null }
|
| double | { "name": "fieldName", "type": ["null","double"], default: null }
|
| map<string,list<string>> | {
"name": "fieldName",
"type": [
"null",
{
"type": "map",
"values": {
"type": "array",
"items": "string"
}
}
],
"default": null
}
|
| list<string> | {
"name": "fieldName",
"type":
[
"null",
{
"type": "array",
"items": "int"
}
],
"default": null
}
|
Casting / parsing¶
Many of the simple values that can be extracted from a request are strings. Possibly, these values are not intended to be strings. Because type information about things like query parameters or path components is lost in a HTTP request, Divolte Collector can only treat these as strings. It is, however, possible to parse string to other primitive or other types in the mapping using this construct:
def i = parse stringValue to int32
In the example above, stringValue is a value of type string and the result value, assigned to i, will be of type int. Note that this is not casting, but string parsing. When the string value cannot be parsed to an int (because it is not a number), then the resulting value will be absent, but no error occurs.
A more complete example is this:
def u = parse referer() to uri // u is of type URI (which is not mappable)
def q = u.query() // q is of type map<string,list<string>>
def s = q.value('foo') // s is of type string if query parameter foo contained a integer number
def i = parse s to int32 // i is of type int
map i onto 'intField' // map it onto the field 'intField'
Because int, long, boolean, etc. are reserved words in Groovy, the mapping DSL uses aliases for casting. These are all the type that can be used for parsing and the corresponding mapping type:
| parsing alias | type |
|---|---|
| int32 | int |
| int64 | long |
| fp32 | float |
| fp64 | double |
| bool | boolean |
| uri | URI |
Conditional mapping (when)¶
Not all incoming requests are the same and usually, different types of requests require different values to be extracted and different fields to be set. This can be achieved using conditional mapping. With conditional mapping any boolean value can be used to conditionally apply a part of the mapping script. This can be done using the following syntax:
when conditionBooleanValue apply {
// Conditional mapping go here
map 'value' onto 'fieldName'
}
A more concrete example of using this construct would be:
when referer().isAbsent() apply {
map true onto 'directTraffic'
}
Here we check whether the referer value is absent and if so, map a literal value onto a boolean field.
As an alternative syntax, it is possible to use a closure that produces the boolean value as well, just like in Mapping values onto fields (map). In this example we check if a query parameter called clientId is present in the location and on that condition perform a mapping:
when {
def u = parse location() to uri
u.query().value('clientId').isPresent()
} apply {
map true onto 'signedInUser'
}
Conditions¶
Any boolean value can be used as a condition. In order to be able to create flexible conditional mappings, the mapping DSL provides a number of methods on values to produce booleans that are useful in conditional mappings, such as equality comparisons and boolean logic:
| Condition | Description |
|---|---|
| value.isPresent() | True if the value is present. See: Value presence and nulls |
| value.isAbsent() | True if the value is absent. See: Value presence and nulls |
| value.equalTo(otherValue) | True if both values are equal. Values must be of the same type. |
| value.equalTo(‘literal’) | True if the value is equal to the given literal. Types other than string are supported as well. |
| booleanValue.and(otherBooleanValue) | True if booleanValue AND otherBooleanValue are true. |
| booleanValue.or(otherBooleanValue) | True if booleanValue OR otherBooleanValue or both are true. |
| not booleanValue | True if booleanValue is false. |
| regexMatcherValue.matches() | True if the regex matches the value. See: Regular expression matching. |
Sections and short circuit¶
Sections are useful for grouping together parts of the mapping that somehow form a logical subset of the entire mapping. This makes it possible to conditionally jump out of a section as well. To define a section, just use the secion keyword followed by a closure that contains the section:
section {
// Section's mappings go here
map 'value' onto 'field'
}
exit¶
The exit() method will, at any point, break out of the enclosing section or, when no enclosing section can be found, break out of the entire mapping script. This can be used to conditionally break out of a section, for example to create a type of first-match-wins scenario:
section {
def u = parse location() to uri
when u.path().equalTo('/home.html') apply {
map 'homepage' onto 'pageType'
exit()
}
when u.path().equalTo('/contact.html') apply {
map 'contactpage' onto 'pageType'
exit()
}
map 'other' onto 'pageType'
}
// other mappings here
There is a optional shorthand syntax for conditionally exiting from a section, which leaves out the apply keyword and closure like this:
when referer().isAbsent() exit()
stop¶
The stop() method will, at any point, stop all further processing and break out of the entire mapping script. This is typically applied conditionally. Generally, it is safer to use sections and exit() instead. Use with care. The stop() method can also be used conditionally, just as anything else:
when referer().isAbsent() {
stop()
}
Or, using shorthand syntax:
when referer().isAbsent stop()
A word on groovy¶
Groovy is a dynamic language for the JVM. This means, amongst other things, that you don’t have to specify the types of variables:
def i = 40
println i + 2
The above snippet will print out 42 as you would expect. Note two things: we never specified that variable i is an int and also, we are not using any parenthese in the println method call. Groovy allows to leave out the parentheses in most method calls. The code above is equal to this snippet:
def i = 42
println(i + 2)
Which in turn is equals to this:
def i = 42
println(i.plus(2))
When chaining sinle argument methods, this works out well. However, with nested method calls, this can be more problematic. Let’s say we have a method called increment which increments the argument by one; so increment(10) will return 11. For example the following will not compile:
println increment 10
But this will:
println(increment(10))
And this won’t:
println(increment 10)
In the Divolte Collector mapping DSL, it is sometimes required to chain method calls. For example when using the result of a casting operation in a mapping. We solve this by accepting a closure that produces a value as result:
map { parse cookie('customer_id') to int32 } onto 'customerId'
This way, you don’t have to add parentheses to all intermediate method calls and we keep the syntax fluent. If you follow these general guidelines, you should be safe:
When calling methods that produce a value, always use parentheses. For example: location(), referer(), partyId()
When deriving a condition or other value from a method that produces a value, also use parenthese. Example:
when location().equalTo('http://www.example.com/') apply { ... } map cookie('example').isPresent() onto 'field' map parsedUri.query().value('foo') onto 'field'When parsing or matching on something, extract it to a variable before using it. This also improves readability:
def myUri = parse location() to uri when myUri.query().value('foo').isPresent() apply { ... } def myMatcher = match '^/foo/bar/([a-z]+)/' against myUri.path() when myMatcher.matches() apply { ... }When casting inline, use the closure syntax for mapping or conditionals:
map { parse cookie('example') to int32 } onto 'field'
Simple values¶
Simple values are pieces of information that are directly extracted from the request without any processing. You can map simple values directly onto fields of the correct type or you can use them in further processing, such as regex matching and extraction or URI parsing.
location¶
| Usage: | map location() onto 'locationField'
|
|---|---|
| Description: | The location of this request: the full address in the address bar of the user’s browser, including the fragment part if this is present (the part after the #). This is different from server side request logs, which will not be able to catch the fragment part. |
| Type: | string |
referer¶
| Usage: | map referer() onto 'refererField'
|
|---|---|
| Description: | The referer of this request. Note that the referer is taken from JavaScript and does not depend on any headers being sent by the browser. The referer will not contain any fragment part that might have been present in the user’s address bar. |
| Type: | string |
firstInSession¶
| Usage: | map firstInSession() onto 'first'
|
|---|---|
| Description: | A boolean flag that is set to true if a new session ID was generated for this request and false otherwise. A value of true indicates that a new session has started. |
| Type: | boolean |
corrupt¶
| Usage: | map corrupt() onto 'detectedCorruption'
|
|---|---|
| Description: | A boolean flag that is set to true when the request checksum does not match the request contents and false otherwise. Whenever a the JavaScript performs a request, it calculates a hash code of all request properties and adds this hash code at the end of the request. On the server side, this hash is calculated again and checked for correctness. Corrupt requests usually occur when intermediate parties try to re-write requests or truncate long URLs (e.g. proxies and anti-virus software can have this habit). |
| Type: | boolean |
duplicate¶
| Usage: | map duplicate() onto 'detectedDuplicate'
|
|---|---|
| Description: | A boolean flag that is set to true when the request is believed to be duplicated and false otherwise. Duplicate detection in Divolte Collector utilizes a probabilistic data structure that has a low false positive and false negative rate. Nonetheless, these can still occur. Duplicate requests are often performed by certain types of anti-virus software and certain proxies. Additionally, sometimes certain browsers go haywire and send the same request large numbers of times (in the tens of thousands). The duplicate flag server as a line of defense against this phenomenon, which is particularly handy in real-time processing where it is not practical to perform de-duplication of the data based on a full data scan. |
| Type: | boolean |
timestamp¶
| Usage: | map timestamp() onto 'timeField'
|
|---|---|
| Description: | The timestamp of the time the the request was received by the server, in milliseconds since the UNIX epoch. |
| Type: | long |
clientTimestamp¶
| Usage: | map clientTimestamp() onto 'timeField'
|
|---|---|
| Description: | The timestamp that was recorded on the client side immediately prior to sending the request, in milliseconds since the UNIX epoch. |
| Type: | long |
remoteHost¶
| Usage: | map remoteHost() onto 'ipAddressField'
|
|---|---|
| Description: | The remote IP address of the request. Depending on configuration, Divolte Collector will use any X-Forwarded-For headers set by intermediate proxies or load balancers. |
| Type: | string |
viewportPixelWidth¶
| Usage: | map viewportPixelWidth() onto 'widthField'
|
|---|---|
| Description: | The width of the client’s browser viewport in pixels. |
| Type: | int |
viewportPixelHeight¶
| Usage: | map viewportPixelHeight() onto 'widthField'
|
|---|---|
| Description: | The height of the client’s browser viewport in pixels. |
| Type: | int |
screenPixelWidth¶
| Usage: | map screenPixelWidth() onto 'widthField'
|
|---|---|
| Description: | The width of the client’s screen in pixels. |
| Type: | int |
screenPixelHeight¶
| Usage: | map screenPixelHeight() onto 'widthField'
|
|---|---|
| Description: | The height of the client’s screen in pixels. |
| Type: | int |
devicePixelRatio¶
| Usage: | map devicePixelRatio() onto 'ratioField'
|
|---|---|
| Description: | The ratio of physical pixels to logical pixels on the client’s device. Some devices use a scaled resolution, meaning that the resolution and the actual available pixels are different. This is common on retina-type displays, with very high pixel density. |
| Type: | int |
partyId¶
| Usage: | map partyId() onto 'partyField'
|
|---|---|
| Description: | A unique identifier stored with the client in a long lived cookie. The party ID identifies a known device. |
| Type: | string |
sessionId¶
| Usage: | map sessionId() onto 'sessionField'
|
|---|---|
| Description: | A unique identifier stored with the client in a cookie that is set to expire after a fixed amount of time (default: 30 minutes). Each new request resets the session expiry time, which means that a new session will start after the session timeout has passed without any activity. |
| Type: | string |
pageViewId¶
| Usage: | map pageViewId() onto 'pageviewField'
|
|---|---|
| Description: | A unique identifier that is generated for each pageview request. |
| Type: | string |
eventId¶
| Usage: | map eventId() onto 'eventField'
|
|---|---|
| Description: | A unique identifier that is created for each event that is fired by taking the pageViewId and appending a monotonically increasing number to it. |
| Type: | string |
userAgentString¶
| Usage: | map userAgentString() onto 'uaField'
|
|---|---|
| Description: | The full user agent identification string as reported by the client’s browser. See User agent parsing on how to extract more meaningful information from this string. |
| Type: | string |
cookie¶
| Usage: | map cookie('cookie_name') onto 'customCookieField'
|
|---|---|
| Description: | The value for a cookie that was sent by the client’s browser in the request. |
| Type: | string |
eventType¶
| Usage: | map eventType() onto 'eventTypeField'
|
|---|---|
| Description: | The type of event that was captured in this request. This defaults to ‘pageView’, but can be overridden when custom events are fired from JavaScript within a page. |
| Type: | string |
Complex values¶
Complex values return objects that you can in turn use to extract derived, simple values from. Complex values are either the result of parsing something (e.g. the user agent string) or matching regular expressions against another value.
eventParameters¶
| Usage: | // on the client in JavaScript:
divolte.signal('myEvent', { foo: 'hello', bar: 42 });
// in the mapping
map eventParameters() onto 'parametersField'
|
|---|---|
| Description: | The value for all parameters that were sent as part of a custom event from JavaScript. Note that these are always strings, regardless of the type used on the client side. Use the following Avro type to map the event parameters: {
"name": "parametersField",
"type": [
"null",
{
"type": "map",
"values": {
"type": "string"
}
}
],
"default": null
}
|
| Type: | map<string,string> |
eventParameters value¶
| Usage: | // on the client in JavaScript:
divolte.signal('myEvent', { foo: 'hello', bar: 42 });
// in the mapping
map eventParameters().value('foo') onto 'fooField'
// or with a cast
map { parse eventParameters().value('bar') to int32 } onto 'barField'
|
|---|---|
| Description: | The value for a parameter that was sent as part of a custom event from JavaScript. Note that this is always a string, regardless of the type used on the client side. In the case that you are certain a parameter has a specific type, you can explicitly cast it as in the example above. |
| Type: | string |
URI¶
| Usage: | def locationUri = parse location() to uri
|
|---|---|
| Description: | Attempts to parse a string into a URI. The most obvious values to use for this are the location() and referer() values, but you can equally do the same with custom event parameters or any other string. If the parser fails to create a URI from a string, than the value will be absent. Note that the parsed URI itself is not directly mappable onto any Avro field. |
| Type: | URI |
URI path¶
| Usage: | def locationUri = parse location() to uri
map locationUri.path() onto 'locationPathField'
|
|---|---|
| Description: | The path component of a URI. Any URL encoded values in the path will be decoded. Keep in mind that if the path contains a encoded / character (%2F), this will also be decoded. Be careful when matching regular expressions against path parameters. |
| Type: | string |
URI rawPath¶
| Usage: | def locationUri = parse location() to uri
map locationUri.rawPath() onto 'locationPathField'
|
|---|---|
| Description: | The path component of a URI. This value is not decoded in any way. |
| Type: | string |
URI scheme¶
| Usage: | def locationUri = parse location() to uri
map locationUri.scheme() onto 'locationSchemeField'
// or check for HTTPS and map onto a boolean field
map locationUri.scheme().equalTo('https') onto 'isSecure'
|
|---|---|
| Description: | The scheme component of a URI. This is the protocol part, such as http or https. |
| Type: | string |
URI host¶
| Usage: | def locationUri = parse location() to uri
map locationUri.host() onto 'locationHostField'
|
|---|---|
| Description: | The host component of a URI. In http://www.example.com/foo/bar, this would be: www.example.com |
| Type: | string |
URI port¶
| Usage: | def locationUri = parse location() to uri
map locationUri.port() onto 'locationPortField'
|
|---|---|
| Description: | The port component of a URI. In http://www.example.com:8080/foo, this would be: 8080. Note that when no port is specified in the URI (e.g. http://www.example.com/foo), this value will be absent. Divolte Collector makes no assumptions about default ports for protocoles. |
| Type: | int |
URI decodedQueryString¶
| Usage: | def locationUri = parse location() to uri
map locationUri.decodedQueryString() onto 'locationQS'
|
|---|---|
| Description: | The full, URL decoded query string of a URI. In http://www.example.com/foo/bar.html?q=hello+world&foo%2Fbar, this would be: “q=hello world&foo/bar”. |
| Type: | string |
URI rawQueryString¶
| Usage: | def locationUri = parse location() to uri
map locationUri.rawQueryString() onto 'locationQS'
|
|---|---|
| Description: | The full, query string of a URI without any decoding. In http://www.example.com/foo/bar.html?q=hello+world&foo%2Fbar, this would be: “q=hello+world&foo%2Fbar”. |
| Type: | string |
URI decodedFragment¶
| Usage: | def locationUri = parse location() to uri
map locationUri.decodedFragment() onto 'locationFragment'
|
|---|---|
| Description: | The full, URL decoded fragment of a URI. In http://www.example.com/foo/#/localpath/?q=hello+world&foo%2Fbar, this would be: “/localpath/?q=hello world&foo/bar”. |
| Type: | string |
URI rawFragment¶
| Usage: | def locationUri = parse location() to uri
map locationUri.rawFragment() onto 'locationFragment'
|
|---|---|
| Description: | The full, fragment of a URI without any decoding. In http://www.example.com/foo/#/localpath/?q=hello+world&foo%2Fbar, this would be: “/localpath/?q=hello+world&foo%2Fbar”. In web applications with rich client side functionality written in JavaScript, it is a common pattern that the fragment of the location is written as a URI again, but without a scheme, host and port. Nonetheless, it is entirely possible to parse the raw fragment of a location into a separate URI again and use this for further mapping. As an example, consider the following: // If location() = 'http://www.example.com/foo/#/local/path/?q=hello+world'
// this would map '/local/path/' onto the field clientSidePath
def locationUri = parse location() to uri
def localUri = parse location().rawFragment() to uri
map localUri.path() onto 'clientSidePath'
|
| Type: | string |
Query strings¶
| Usage: | def locationUri = parse location() to uri
def locationQuery = locationUri.query()
map locationQuery onto 'locationQueryParameters'
|
|---|---|
| Description: | The query string from a URI parsed into a map of value lists. In the resulting map, the keys are the parameter names of the query string and the values are lists of strings. Lists are required, as a query parameter can have multiple values (by being present more than once). In order to map all the query parameters directly onto a Avro field, the field must be typed as a map of string lists, possibly a union with null, to have a sensible default when no query string is possible. In a Avro schema definition, the following field definition can be a target field for the query parameters: {
"name": "uriQuery",
"type": [
"null",
{
"type": "map",
"values": {
"type": "array",
"items": "string"
}
}
],
"default": null
}
|
| Type: | map<string,list<string>> |
Query string value¶
| Usage: | def locationUri = parse location() to uri
def locationQuery = locationUri.query()
map locationQuery.value('foo') onto 'fooQueryParameter'
|
|---|---|
| Description: | The first value found for a query parameter. This value is URL decoded. |
| Type: | string |
Query string valueList¶
| Usage: | def locationUri = parse location() to uri
def locationQuery = locationUri.query()
map locationQuery.valueList('foo') onto 'fooQueryParameterValues'
|
|---|---|
| Description: | A list of all values found for a query parameter name. These values are URL decoded. |
| Type: | list<string> |
Regular expression matching¶
| Usage: | def matcher = match '/foo/bar/([a-z]+).html$' against location()
|
|---|---|
| Description: | Matches the given regular expression against a value. The result of this can not be directly mapped onto a Avro field, but can be used to extract capture groups or conditionally perform a mapping if the pattern is a match. Often it is required to perform non-trivial partial extractions against strings that are taken from the requests. One example would be matching the path of the location with a wild card. It is not recommended to match patterns against the location() or referer() values directly; instead consider parsing out relevant parts of the URI first using URI parsing. In the following example, the matching is much more robust in the presence of unexpected query parameters or fragments compared to matching against the entire location string: def locationUri = parse location() to uri
def pathMatcher = match '^/foo/bar/([a-z]+).html$' against locationUri.path()
when pathMatcher.matches() apply {
map 'fooBarPage' onto 'pageTypeField'
map pathMatcher.group(1) onto 'pageNameField'
}
|
| Type: | Matcher |
Regex matches¶
| Usage: | def matcher = match '/foo/bar/([a-z]+).html$' against location()
// use in conditional mapping
when matcher.matches() apply {
map 'fooBarPage' onto 'pageTypeField'
}
// or map directly onto a boolean field
map matcher.matches() onto 'isFooBarPage'
|
|---|---|
| Description: | True when the pattern matches the value or false otherwise. In case the target value is absent, this will produce false. |
| Type: | boolean |
Regex group¶
| Usage: | // Using group number
def matcher = match '/foo/bar/([a-z]+).html$' against location()
map matcher.group(1) onto 'pageName'
// Using named capture groups
def matcher = match '/foo/bar/(?<pageName>[a-z]+).html$' against location()
map matcher.group('pageName') onto 'pageName'
|
|---|---|
| Description: | The value from a capture group in a regular expression pattern if the pattern matches, absent otherwise. Groups can be identified by their group number, starting from 1 as the first group or using named capture groups. |
| Type: | string |
HTTP headers¶
| Usage: | map header('header-name') onto 'fieldName'
|
|---|---|
| Description: | The list of all values associated with the given HTTP header from the incoming request. A HTTP header can be present in a request multiple times, yielding multiple values for the same header name; these are returned as a list. The Avro type of the target field for this mapping must be a list of string: {
"name": "headers",
"type":
[
"null",
{
"type": "array",
"items": ["string"]
}
],
"default": null
}
Note that the array field in Avro itself is nullable and has a default value of null, whereas the items in the array are not nullable. The latter is not required, because when te header is present, the elements in the list are guaranteed to be present. |
| Type: | list<string> |
HTTP header first¶
| Usage: | map header('header-name').first() onto 'fieldName'
|
|---|---|
| Description: | The first of all values associated with the given HTTP header from the incoming request. A HTTP header can be present in a request multiple times, yielding multiple values for the same header name. This returns the first value in that list. |
| Type: | string |
HTTP header last¶
| Usage: | map header('header-name').last() onto 'fieldName'
|
|---|---|
| Description: | The last of all values associated with the given HTTP header from the incoming request. A HTTP header can be present in a request multiple times, yielding multiple values for the same header name. This returns the last value in that list. |
| Type: | string |
HTTP header commaSeparated¶
| Usage: | map header('header-name').commaSeparated() onto 'fieldName'
|
|---|---|
| Description: | The comma separated string of all values associated with the given HTTP header from the incoming request. A HTTP header can be present in a request multiple times, yielding multiple values for the same header name. This joins that list using a comma as separator. |
| Type: | string |
User agent parsing¶
| Usage: | def ua = userAgent()
|
|---|---|
| Description: | Attempts to parse a the result of userAgentString string into a user agent object. Note that this result is not directly mappable onto any Avro field. Instead, the subfields from this object, described below, can be mapped onto fields. When the parsing of the user agent string fails, either because the user agent is unknown or malformed, or because the user agent was not sent by the browser, this value and all subfields’ values are absent. |
| Type: | ReadableUserAgent |
User agent name¶
| Usage: | map userAgent().name() onto 'uaNameField'
|
|---|---|
| Description: | The canonical name for the parsed user agent. E.g. ‘Chrome’ for Google Chrome browsers. |
| Type: | string |
User agent family¶
| Usage: | map userAgent().family() onto 'uaFamilyField'
|
|---|---|
| Description: | The canonical name for the family of the parsed user agent. E.g. ‘Mobile Safari’ for Apple’s mobile browser. |
| Type: | string |
User agent vendor¶
| Usage: | map userAgent().vendor() onto 'uaVendorField'
|
|---|---|
| Description: | The name of the company or oganisation that produces the user agent software. E.g. ‘Google Inc.’ for Google Chrome browsers. |
| Type: | string |
User agent type¶
| Usage: | map userAgent().type() onto 'uaTypeField'
|
|---|---|
| Description: | The type of user agent that was used. E.g. ‘Browser’ for desktop browsers. |
| Type: | string |
User agent version¶
| Usage: | map userAgent().version() onto 'uaVersionField'
|
|---|---|
| Description: | The version string of the user agent software. E.g. ‘39.0.2171.71’ for Google Chrome 39. |
| Type: | string |
User agent device category¶
| Usage: | map userAgent().deviceCategory() onto 'uaDeviceCategoryField'
|
|---|---|
| Description: | The type of device that the user agent runs on. E.g. ‘Tablet’ for a tablet based browser. |
| Type: | string |
User agent OS family¶
| Usage: | map userAgent().osFamily() onto 'uaOSFamilyField'
|
|---|---|
| Description: | The operating system family that the user agent runs on. E.g. ‘OS X’ for a Apple OS X based desktop. |
| Type: | string |
User agent OS version¶
| Usage: | map userAgent().osVersion() onto 'uaOSVersionField'
|
|---|---|
| Description: | The version string of the operating system that the user agent runs on. E.g. ‘10.10.1’ for Max OS X 10.10.1. |
| Type: | string |
User agent OS vendor¶
| Usage: | map userAgent().osVendor() onto 'uaOSVendorField'
|
|---|---|
| Description: | The name of the company or oganisation that produces the operating system that the user agent software runs on. E.g. ‘Apple Computer, Inc.’ for Apple Mac OS X. |
| Type: | string |
ip2geo¶
| Usage: | // uses the remoteHost as IP address to lookup
def ua = ip2geo()
// If a load balancer sets custom headers for IP addresses, use like this
def ip = header('X-Custom-Header').first()
def myUa = ip2geo(ip)
|
|---|---|
| Description: | Attempts to turn a IPv4 address into a geo location by performing a lookup into a configured MaxMind GeoIP City database. This database is not distributed with Divolte Collector, but must be provided separately. See the Configuration chapter for more details on this. Note that this result is not directly mappable onto any Avro field. Instead, the subfields from this object, described below, can be mapped onto fields. When the lookup for a IP address fails or when the argument is not a IPv4 address, this value and all subfields’ values are absent. |
| Type: | CityResponse |
Geo IP cityId¶
| Usage: | map ip2geo().cityId() onto 'cityIdField'
|
|---|---|
| Description: | The City ID for the geo location as known by http://www.geonames.org/. |
| Type: | int |
Geo IP cityName¶
| Usage: | map ip2geo().cityName() onto 'cityNameField'
|
|---|---|
| Description: | The city name for the geo location in English. |
| Type: | string |
Geo IP continentCode¶
| Usage: | map ip2geo().continentCode() onto 'continentCodeField'
|
|---|---|
| Description: | The ISO continent code for the geo location. |
| Type: | string |
Geo IP continentId¶
| Usage: | map ip2geo().continentId() onto 'continentIdField'
|
|---|---|
| Description: | The Continent Id for the geo location as known by http://www.geonames.org/. |
| Type: | int |
Geo IP continentName¶
| Usage: | map ip2geo().continentName() onto 'continentNameField'
|
|---|---|
| Description: | The continent name for the geo location in English. |
| Type: | string |
Geo IP countryCode¶
| Usage: | map ip2geo().countryCode() onto 'countryCodeField'
|
|---|---|
| Description: | The ISO country code for the geo location. |
| Type: | string |
Geo IP countryId¶
| Usage: | map ip2geo().countryId() onto 'countryIdField'
|
|---|---|
| Description: | The Country Id for the geo location as known by http://www.geonames.org/. |
| Type: | int |
Geo IP countryName¶
| Usage: | map ip2geo().countryName() onto 'countryNameField'
|
|---|---|
| Description: | The country name for the geo location in English. |
| Type: | string |
Geo IP latitude¶
| Usage: | map ip2geo().latitude() onto 'latitudeField'
|
|---|---|
| Description: | The latitude for the geo location in English. |
| Type: | double |
Geo IP longitude¶
| Usage: | map ip2geo().longitude() onto 'longitudeField'
|
|---|---|
| Description: | The longitude for the geo location in English. |
| Type: | double |
Geo IP metroCode¶
| Usage: | map ip2geo().metroCode() onto 'metroCodeField'
|
|---|---|
| Description: | The ISO metro code for the geo location. |
| Type: | string |
Geo IP timeZone¶
| Usage: | map ip2geo().timeZone() onto 'timeZoneField'
|
|---|---|
| Description: | The time zone name for the geo location as found in the IANA Time Zone Database. |
| Type: | string |
Geo IP mostSpecificSubdivisionCode¶
| Usage: | map ip2geo().mostSpecificSubdivisionCode() onto 'mostSpecificSubdivisionCodeField'
|
|---|---|
| Description: | The ISO code for the most specific subdivision known for the geo location. |
| Type: | string |
Geo IP mostSpecificSubdivisionId¶
| Usage: | map ip2geo().mostSpecificSubdivisionId() onto 'mostSpecificSubdivisionIdField'
|
|---|---|
| Description: | The ID for the most specific subdivision known for the geo location as known by http://www.geonames.org/. |
| Type: | int |
Geo IP mostSpecificSubdivisionName¶
| Usage: | map ip2geo().mostSpecificSubdivisionName() onto 'mostSpecificSubdivisionNameField'
|
|---|---|
| Description: | The name for the most specific subdivision known for the geo location in English. |
| Type: | string |
Geo IP postalCode¶
| Usage: | map ip2geo().postalCode() onto 'postalCodeField'
|
|---|---|
| Description: | The postal code for the geo location. |
| Type: | string |
Geo IP subdivisionCodes¶
| Usage: | map ip2geo().subdivisionCodes() onto 'subdivisionCodesField'
|
|---|---|
| Description: | The ISO codes for all subdivisions for the geo location in order from least specific to most specific. |
| Type: | list<string> |
Geo IP subdivisionIds¶
| Usage: | map ip2geo().subdivisionIds() onto 'subdivisionIdsFields'
|
|---|---|
| Description: | The IDs for all subdivisions for the geo location in order from least specific to most specific as known by http://www.geonames.org/. |
| Type: | list<string> |
Geo IP subdivisionNames¶
| Usage: | map ip2geo().subdivisionNames() onto 'subdivisionNames'
|
|---|---|
| Description: | The names in English for all subdivisions for the geo location in order from least specific to most specific. |
| Type: | list<string> |